Research Highlights
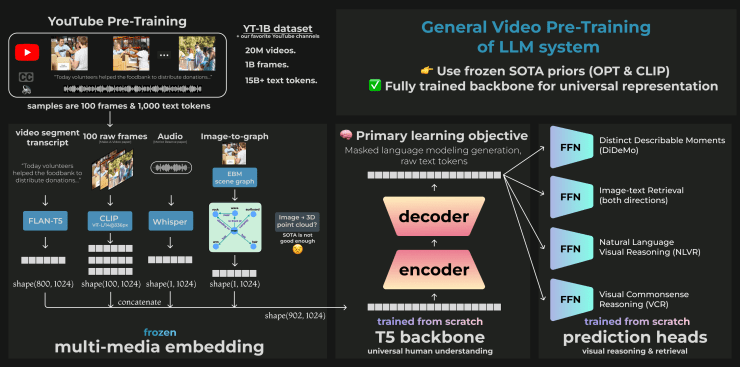
I customized Huggingface’s implementation of T5 to fit the “embedding →backbone → task-specific head” design pattern popularized by DETER and AlphaFold2, which was a popular pattern at Tesla AI day 2022. The idea is to stand on the shoulders of (pre-trained) giants; my video-to-text model extracts embeddings for dialogue, image, audio, and SceneGraph from the best SoTA models and forces a T5 “backbone” transformer to combine these multimodal embeddings to produce T5’s typical conditional language modeling text generations. It’s a mixture of pre-trained experts that’s very good at video-QA (TVQA), and precise video retrieval (DiDeMo).
I won “best project of the year” in two senior seminar courses at UIUC: Advanced NLP & Meta-Learning in AI.
I’m proud of this for my creative new architecture, successfully editing the internals of T5, and overcoming massive challenges of scale as an independent researcher.
Editing model internals
- Added 2 supplementary contrastive self-supervised loss terms to force the model to learn “temporal frame ordering” i.e. the correct order of video frames in a short sequence, and “frame-caption matching” to force the model to associate snippets of video dialogue with the correct video frame.
- Customized the Hugging Face implementation of T5 by adding modality encodings, similar to position encodings, to indicate Text/Image/Audio/Scene-graph embeddings.
Architecture improvements
- My proposed architecture of “multimodal sentences” has since been implemented, in a limited 2-modality fashion, in PALM-E and Vid2Seq from Google, and many more listed on my Twitter announcement.
Large Data & Compute
- Massive data engineering effort: download 3M YouTube videos, 110 TB of storage. 12 GPU-years of parallel & distributed inference to preprocess the dataset with inference via CLIP, Whisper, etc.. Inference performance optimization + parallel in-place data updates forced a carefully considered distributed database design.
- Massive training effort: 10 GPU years per epoch of training (or 10 days across 400 A100s). Thanks to a grant I secured for this work from the National Science Foundation and NCSA Delta supercomputer.
